les données et les librairies¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_csv('data/titanic.csv', index_col=0)
df.head(3)introduction¶
groupement par critère unique¶
# le code
df['Sex'].unique()array(['male', 'female'], dtype=object)# le code
by_sex = df.groupby(by='Sex')
by_sex<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f97d773e7e0>accès aux sous-dataframes¶
# les tailles des morceaux
by_sex.size()Sex
female 314
male 577
dtype: int64# la somme est correcte
sum(by_sex.size()) == len(df)True# pour itérer 'à la main'
for group, subdf in by_sex:
print(group, subdf.shape)female (314, 11)
male (577, 11)
proxying : propagation de fonctions sur les sous-dataframes¶
# souvent on traite un groupby comme une dataframe
# ce qui a l'effet d'appliquer l'opération (ici ['Age'])
# à toutes les sous-dataframe
by_sex.Age.max()Sex
female 63.0
male 80.0
Name: Age, dtype: float64by_sex[['Survived', 'Fare']].sum()accéder à un groupe¶
by_sex.get_group('female').head(4)groupement multi-critères¶
# le code
by_class_sex = df.groupby(['Pclass', 'Sex'])
by_class_sex.size()Pclass Sex
1 female 94
male 122
2 female 76
male 108
3 female 144
male 347
dtype: int64multi-index pour les multi-critères¶
# le code
type(by_class_sex.size())pandas.core.series.Seriesdf.groupby(['Pclass', 'Sex']).size().indexMultiIndex([(1, 'female'),
(1, 'male'),
(2, 'female'),
(2, 'male'),
(3, 'female'),
(3, 'male')],
names=['Pclass', 'Sex'])# le code
computed_index = {(i, j) for i in df['Pclass'].unique() for j in df['Sex'].unique()}
computed_index{(np.int64(1), 'female'),
(np.int64(1), 'male'),
(np.int64(2), 'female'),
(np.int64(2), 'male'),
(np.int64(3), 'female'),
(np.int64(3), 'male')}# pour vérifier
computed_index == set(df.groupby(['Pclass', 'Sex']).size().index)Trueles éléments de l’index sont des tuples¶
# le code
for (class_, sex), subdf in by_class_sex:
print(f"there were {len(subdf)} {sex} in class {class_} ")there were 94 female in class 1
there were 122 male in class 1
there were 76 female in class 2
there were 108 male in class 2
there were 144 female in class 3
there were 347 male in class 3
display de head() avec IPython¶
# le code : c'est moche
#for group, subdf in by_class_sex:
# print(group, subdf.head(1))# le code
import IPython
for group, subdf in by_class_sex:
print(group)
IPython.display.display(subdf.head(1))exercice sur les partitions groupby¶
(déplacé en fin de notebook)
intervalles de valeurs d’une colonne¶
introduction¶
# le code (à décommenter pour essayer)
# pd.cut?découpage en intervalles d’une colonne¶
# le code
pd.cut(df['Age'], bins=[0, 12, 19, 55, 100])PassengerId
552 (19.0, 55.0]
638 (19.0, 55.0]
499 (19.0, 55.0]
261 NaN
395 (19.0, 55.0]
...
463 (19.0, 55.0]
287 (19.0, 55.0]
326 (19.0, 55.0]
396 (19.0, 55.0]
832 (0.0, 12.0]
Name: Age, Length: 891, dtype: category
Categories (4, interval[int64, right]): [(0, 12] < (12, 19] < (19, 55] < (55, 100]]# le code
# pareil mais avec des labels ad-hoc
age_class_series = pd.cut(df['Age'], bins=[0, 12, 19, 55, 100],
labels=['child', 'young', 'adult', '55+'])
age_class_seriesPassengerId
552 adult
638 adult
499 adult
261 NaN
395 adult
...
463 adult
287 adult
326 adult
396 adult
832 child
Name: Age, Length: 891, dtype: category
Categories (4, object): ['child' < 'young' < 'adult' < '55+']# pour ranger ça dans une nouvelle colonne
df['Age-class'] = age_class_series# le type est une catégorie, il est bien ordonné
age_class_series.dtypeCategoricalDtype(categories=['child', 'young', 'adult', '55+'], ordered=True, categories_dtype=object)# pour effacer la colonne 'Age'
print("avant", df.columns)
del df['Age']
print("après", df.columns)
# on peut utiliser aussi df.drop
# df.drop('Age', axis=1, inplace=True)avant Index(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Embarked', 'Age-class'],
dtype='object')
après Index(['Survived', 'Pclass', 'Name', 'Sex', 'SibSp', 'Parch', 'Ticket', 'Fare',
'Cabin', 'Embarked', 'Age-class'],
dtype='object')
groupement avec ces intervalles¶
# le code
df.groupby(['Age-class', 'Survived']).size()/tmp/ipykernel_2542/1068646229.py:2: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
df.groupby(['Age-class', 'Survived']).size()
Age-class Survived
child 0 29
1 40
young 0 56
1 39
adult 0 311
1 199
55+ 0 28
1 12
dtype: int64pivot_table()¶
# df.pivot_table?# pour obtenir la table ci-dessus
df.pivot_table(
values='Survived',
index='Pclass',
columns='Sex',
)pivot_table() et agrégation¶
# votre codepivot_table() et multi-index¶
# relisons depuis le fichier pour être sûr d'avoir la colonne 'Age'
df = pd.read_csv('data/titanic.csv')# votre code
# plusieurs values
# df2 = ...
# pensez à observer les index du résultat
# df2.columns
# df2.index# votre code
# plusieurs columns
# df3 = ...
# pensez à observer les index du résultat
# df3.columns
# df3.index# votre code
# plusieurs index
# df4 = ...
# pensez à observer les index du résultat
# df4.columns
# df4.indexexercice sur pivot_table()¶
df = pd.read_csv('data/wine.csv')
df.head(2)- affichez les valeurs min, max, et moyenne, de la colonne ‘magnesium’
# votre code- définissez deux catégories selon que le magnesium est en dessous ou au-dessus de la moyenne (qu’on appelle
mag-lowetmag-high); rangez le résultat dans une colonnemag-cat
# votre code- calculez cette table
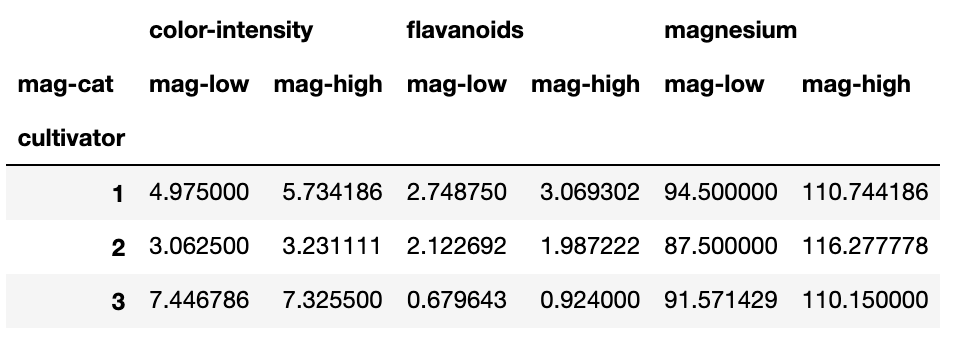
accès aux groupes¶
# on se remet dans le contexte
df = pd.read_csv('data/titanic.csv', index_col=0)
by_sex = df.groupby(by='Sex')# le code
# on peut itérer directement sur le groupby
for group, indexes in by_sex:
print(f"==== {group}\n{df.loc[:, 'Name'].iloc[:3]}")==== female
PassengerId
552 Sharp, Mr. Percival James R
638 Collyer, Mr. Harvey
499 Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
Name: Name, dtype: object
==== male
PassengerId
552 Sharp, Mr. Percival James R
638 Collyer, Mr. Harvey
499 Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
Name: Name, dtype: object
# le code
by_sex.get_group('female').head(3)groupby.filter() - optionnel¶
pour enlever de la dataframe des lignes correspondants à des groupes qui vérifient une certaine propriété
on récupère comme résultat une dataframe (et non pas un groupby comme on aurait pu le penser)
titanic = pd.read_csv("data/titanic.csv")
df = titanic.copy()
gb = df.groupby(by=['Sex', 'Pclass'])
print(f"titanic has {len(df)} items")
for group, subdf in gb:
print(f"group {group} has {len(subdf)} matches")titanic has 891 items
group ('female', np.int64(1)) has 94 matches
group ('female', np.int64(2)) has 76 matches
group ('female', np.int64(3)) has 144 matches
group ('male', np.int64(1)) has 122 matches
group ('male', np.int64(2)) has 108 matches
group ('male', np.int64(3)) has 347 matches
imaginons qu’on ne veuille garder que les groupes qui ont un nombre pair de membres
c’est un peu tiré par les cheveux, mais il n’y a qu’un seul groupe avec un cardinal impair
et donc c’est facile de vérifier qu’on fait bien le travail, on doit trouver 891 - 347 = 544 éléments
on ferait alors tout simplement
# construire une dataframe ne contenant que les groupes
# qui satisfont une certaine condition
extract = gb.filter(lambda df: len(df) %2 == 0)
print(f"the extract has {len(extract)} items left")the extract has 544 items left
groupby.transform() - optionnel¶
pour appliquer aux différents groupes une fonction qui prend en compte les éléments du groupe
exemples d’application typiques:
- centrer chacun des groupes autour de la moyenne (du groupe)
- remplacer les NaN par la moyenne du groupe
# centrons la colonne des ages **groupe par groupe**
# avec nos 6 groupes habituels
# à nouveau ce n'est sans doute pas très utile en pratique, mais bon
df = titanic.copy()
gb = df.groupby(by=['Sex', 'Pclass'])
# on retire à chaque Age la moyenne d'age **du groupe**
df['Age'] = gb['Age'].transform(lambda df: df-df.mean())
df.head(3)# utilisons la même approche pour remplir les ages manquants
# par la moyenne de chaque groupe
df = titanic.copy()
gb = df.groupby(by=['Sex', 'Pclass'])
# pour pouvoir vérifier qu'on a bien fait le job
print(f"===== avant: on a {sum(df['Age'].isna())} âges indéterminés")
print(f"et les moyennes d'âges par groupe sont de")
IPython.display.display(df.pivot_table(values="Age", index="Sex", columns="Pclass"))
# on remplit
df['Age'] = df['Age'].fillna(gb['Age'].transform('mean'))
# on n'a plus de NaN et les moyennes sont inchangées
print(f"===== après: on a {sum(df['Age'].isna())} ages indéterminés")
print(f"et les moyennes d'âges par groupe sont de")
IPython.display.display(df.pivot_table(values="Age", index="Sex", columns="Pclass"))pour résumer¶
- pour faire des groupements multi-critères on utilise
df.groupby()- qui renvoie un objet de type
GroupByou similaire
- qui renvoie un objet de type
- qu’on utilise généralement comme un proxy
- qui va propager les traitements sur les différents “morceaux”
- que l’on peut agréger ensuite “normalement”
- lorsqu’on utilise plusieurs critères les index deviennent des MultiIndex
- c’est-à-dire dont les valeurs sont des tuples
- avec
pivot_table()on peut facilement obtenir des tables de synthèse- en fait,
pivot_table()utilisegroupbysans le dire - (et remet les résultats en forme grâce à
unstack(), mais c’est pour les avancés...)
- en fait,
pour en savoir plus¶
pour creuser cette notion de
stack()/unstack(), et commentpivot_table()s’en sert, voyez ce document
https://flotpython -exos -ds .readthedocs .io /en /main /pandas -howtos /pivot -unstack -groupby /HOWTO -pivot -unstack -groupby -nb .html on recommande la lecture de cet article dans la documentation
pandas, qui approfondit le sujet et notamment la notion desplit-apply-combine
(qui rappelle, de loin, la notion de map-reduce)
https://pandas .pydata .org /pandas -docs /stable /user _guide /groupby .html
exercice sur les partitions groupby¶
(déplacé en fin de notebook)
on veut calculer la partition avec, dans cet ordre, la classe Pclass, le genre Sex, et l’état de survie Survived
- sans calculer la partition
proposez une manière de calculez le nombre probable de sous parties dans la partition
# votre code- calculez la partition avec
pandas.DataFrame.groupby
et affichez les nombres d’items par groupe
# votre code- affichez la dataframe des entrées pour les femmes qui ont péri et qui voyagaient en 1ère classe
# votre code- révision
refaites la même extraction sans utiliser ungroupby()en utilisant les conditions
# votre codepour les élèves avancés
créez undictavec les taux de survie par genre dans chaque classevous devez obtenir quelque chose de ce genre
{('female', 1): 0.96,
('female', 2): 0.92,
('female', 3): 0.5,
('male', 1): 0.36,
('male', 2): 0.15,
('male', 3): 0.13}# votre code- pour les élèves avancés
créez à partir de cedictunepandas.Series
avec comme nom'taux de survie par genre dans chaque classe'
indice: comme tous les types en Pythonpd.Series()permet de créer des objets par programme
voyez la documentation avecpd.Series?
# votre code