import pandas as pd
import numpy as np
import matplotlib.pyplot as pltles types de base¶
la version Python¶
# pas très PEP8 la librairie datetime...
from datetime import datetime# dans le module datetime se trouve la classe datetime
# help(datetime)la version numpy¶
la version pandas¶
exercices: le cours de l’action amazon¶
vous avez peut-être remarqué que read_csv propose des (tas d’) options pour la gestion des instants (notamment le paramètre parse_dates)
dans un premier temps, nous allons rester loin de ce genre de features,
et dans cet exercice nous allons procéder en deux temps, en combinant pd.read_csv et pd.to_datetime
# pd.read_csv?# pd.to_datetime?exercice 1: read_csv¶
- lire le fichier de données
data/Amazon.csvavecread_csv()
attention, le fichier contient 3 premières lignes de commentaires qu’il convient d’ignorer complètement - affichez les types des colonnes
que penser du type de la colonneDate?
- lire le fichier de données
# à vousexercice 2: pd.to_datetime()¶
- traduisez la colonne
Datedans le type adéquat - affichez le nouveau type de la colonne
- ça peut être intéressant de regarder à la fois
dtypessur la dataframe etdtypesur la série (voir la note ci-dessous) - en option (pour les avancés): sauriez-vous passer à
to_datetimele paramètreformatqui va bien ? sachant que c’est une pratique très recommandée pour éviter les embrouilles
- traduisez la colonne
plusieurs choses là pour les curieux
- la première est que
pandasutilise les types de donnéesnumpy
enpandas, quand vous demandez le type des données d’une colonne, vous pouvez obtenir un nom de typenumpy - la seconde est que la
repr()et lastr()du typenp.datetime64sont différentes
(lareprdépend de votre ordinateur ‘<’ est pour little-endian, ‘M’ est le le code caractère du type datetime et 8 la taille mémoire en octets)dt = np.datetime64("2023-09-12 15:30:00.000000000") # nano secondes print(repr(dt.dtype)) -> dtype('<M8[ns]') (M est le code caractère du type datetime) print(str(dt.dtype)) -> datetime64[ns]
# à vousexercice 3: NaT¶
- comparez l’affichage de la première ligne avec celui d’avant la conversion
que remarquez-vous ? - supprimer les lignes pour lesquelles le champ
Dateest inconnu
- comparez l’affichage de la première ligne avec celui d’avant la conversion
pour vérifier vos résultats: le nombre de lignes doit passer de 5852 à 5828
# à vousexercice 4: l’accessor .dt¶
comme on l’a déjà vu avec .str et .cat
il existe un accesseur .dt pour appliquer sur une série de type Timestamp des attributs qui lui sont spécifiques
- en utilisant cet accesseur, ajoutez à la dataframe une colonne qui contient uniquement l’année des dates
- pour les avancés: en utilisant cet accesseur, ajoutez à la dataframe une colonne qui contient le jour de la semaine
où lundi vaut 0, mardi 1, ...
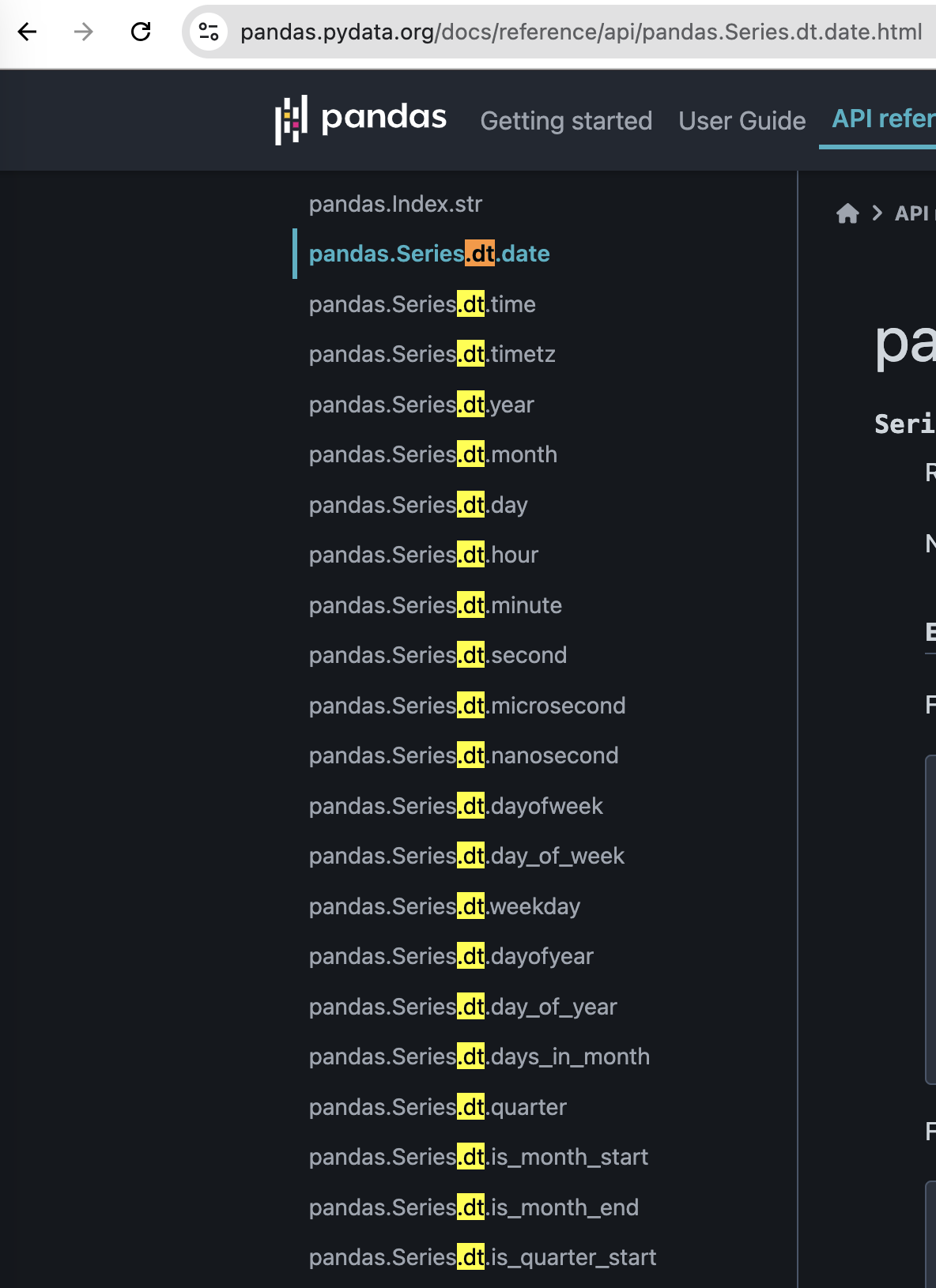
beaucoup d’attributs disponibles
bizarrement on ne trouve pas facilement la liste des attributs disponibles, voici un screenshot qui en montre une (toute petite) partie
# à vousexercice 5: indexons par les dates¶
- mettez la colonne
Datecomme index
et triez la dataframe selon cet index (ça semble être déjà le cas, mais en est-on bien sûr ?)
pour les avancés, question subsidiaire:
le fait de trier les dates va-t-il changer quelque chose à l’affichage des points e.g (Date, valeur de l’action) ?
va-t-il changer quelque chose lorsqu’on va vouloir sélectionner des plages de temps à base de slicing (.loc) ?
# à vousexercice 6: plotting¶
- plottez la valeur de l’action au cours du temps
- sur un même diagramme, les deux cours
HighetLow - ensuite sur deux diagrammes séparés
indice
on pourrait bien sûr utiliser plt.plot()
mais ici on vous invite à utiliser directement la méthode plot sur une DataFrame, vous verrez que c’est beaucoup plus simple !
# ceci nécessite un pip install ipympl
# décommentez pour essayer la visu interactive
%matplotlib ipympl# pour changer la taille des figures par défaut
plt.rcParams["figure.figsize"] = (7, 2)cols = ['High', 'Low']# à vousslicing avec des dates¶
# on recharge pour être sûr
df = pd.read_csv('data/Amazon.csv', skiprows=3)
df['Date'] = pd.to_datetime(df.Date)
df.dropna(subset=['Date'], inplace=True)
df.set_index('Date', inplace=True)
df.head(2)# et ça va jusque
df.tail(2)# première commodité: on peut utiliser des chaines
# pas besoin de mettre des objet Timestamp dans le slice
# les entrées entre le 1er avril 2020 et le 30 juin 2020
# rappel: comme on utilise .loc c'est inclus
# on coupe aux 3 premiers pour ne pas envahir l'écran
df.loc['2020-04-01' : '2020-06-30'].head(3)# mais en fait c'est encore plus simple d'écrire ce qui suit
# qui signifie, de avril à juin, toujours inclusivement
df.loc['2020-04' : '2020-06'].tail(3)# toutes les données de l'année 2019
df.loc['2019'].head(3)# à vous
# filtrer à partir du 1er janvier 2019 jusqu'à la fin des donnéesaggrégations: resample() et rolling()¶
resample()¶
exemple 1: le supermarché¶
dans un supermarché, on vous donne une table avec une ligne par passage à la caisse (rien de régulier, donc)
on veut calculer le chiffre d’affaires par tranche horaire
un simple resample sur 1 heure, en agrégant avec la somme, fournit le résultat
exemple 2: ré-échantillonner un signal sonore¶
vous avez un signal échantillonné à 44.100 kHz et vous voulez le ré-échantillonner (littéralement: resample) à une fréquence 4 fois plus basse.
il suffit de faire un resample avec une durée de corbeille égale à exactement 4 x la période de la fréquence originale, et agréger avec la moyenne
même type d’usages: to_period()¶
avec resample() on peut donc grouper les données par période
signalons un autre outil qui peut aider à faire cela aussi en pandas, il s’agit de to_period() qui convertit un Timestamp en Period (un intervalle de temps), ce qui permet de faire ensuite un groupby() sur ces périodes.
voici un exemple simple pour illustrer cela;
# une table contenant des données éparpillées sur l'année 2024
ticks = pd.read_csv('data/ticks.csv')
ticks['time'] = pd.to_datetime(ticks.time)
ticks.head(4)avec to_period(), on peut facilement ajouter une colonne qui va contenir, disons par exemple le mois calendaire correspondant
ticks['month'] = ticks.time.dt.to_period('M')
ticks.head(4)ce qu’il faut remarquer c’est que les nouveaux champs sont donc de type Period, qui contient un début et une fin (et pas simplement un instant comme un Datetime)
ticks.dtypestime datetime64[ns]
amount int64
category object
month period[M]
dtype: objectrolling()¶
au centre ou à droite
par défaut rolling attache la valeur à la fin de l’intervalle, ou dit autrement il va grouper les données qui sont à gauche du point dont on parle
(on peut demander aussi de l’attacher au centre de l’intervalle, comme on l’a fait sur la figure)
attention aux unités !
pour exprimer la durée de la fenêtre avec rolling(), il apparait qu’on ne peut pas utiliser les unités W, M ou Y qui sont, semble-t-il, susceptibles de varier en durée en fonction du moment de référence (pour le mois et l’année, ok, mais la semaine ?!?)
honnêtement c’est assez oiseux, notamment parce que resample() ne semble pas sujet à cette restriction..
exemple 1: visualiser l’évolution sur une année¶
vous voulez visualiser l’évolution d’une grandeur “d’une année sur l’autre”
on va faire un rolling avec une période d’un an
si on appelle la fonction de départ, et le rolling sur un an
(avec la somme comme agrégation pour simplifier les équations), on va avoir
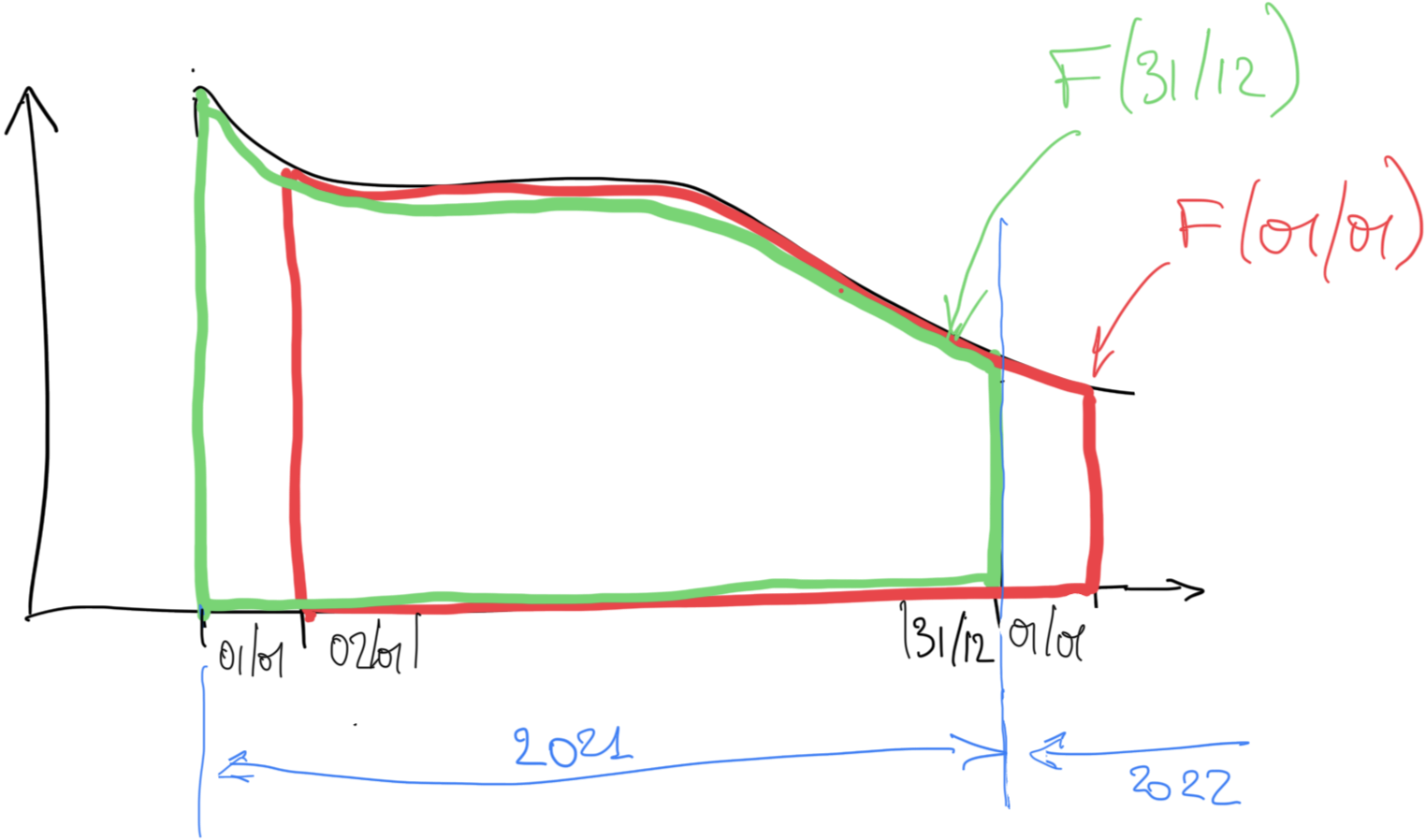
calculons le rolling pour deux jours consécutifs; avec la convention qu’on fait une rolling sur le passé (le défaut, donc) on a
et donc la différence pour F entre deux jours consécutifs vaut
ce qui signifie que
la dérivée de (la différence d’un jour à l’autre), c’est l’évolution de mais d’une année sur l’autre
exemple 2: effet lissant¶
pour bien voir l’effet ‘lissant’ de la fenêtre glissante, prenons des données synthétiques:
import numpy as np# c'est l'occasion de voir comment créer des timeseries par programme
# ici 100 jours consécutifs
date_index = pd.date_range('2018-01-01', periods=100)
# un battement
X = np.arange(100)
s = pd.Series(10*np.cos(X/10) + 2*np.cos(X), index=date_index)
plt.figure()
s.plot();voici l’effet du rolling avec des fenêtres de 1 semaine et 4 semaines
rolling_7 = s.rolling(window=pd.Timedelta(7, 'D'), center=True).mean()
rolling_28 = s.rolling(window=pd.Timedelta(28, 'D'), center=True).mean()ici on a choisi d’attacher le résultat (de la moyenne de la corbeille) au centre de la corbeille
# pour afficher les 3 courbes à la fois
pd.DataFrame({
'original': s,
'roll 7D': rolling_7,
'roll 28D': rolling_28,
}).plot();les bornes¶
juste pour bien illustrer le comportement aux bornes, voici
le nombre de points dans la rolling: autant de corbeilles que de points (on le voit déjà ci-dessus)
et le nombre de points par corbeille: constant, sauf aux extrémités
# exactement autant de corbeilles que de points
len(s), len(rolling_7)(100, 100)# le nombre de points par corbeille
count_28 = s.rolling(window=pd.Timedelta(28, 'D'),
center=True).count()
pd.DataFrame({'points-per-bin-28': count_28}).plot();exercices / digression¶
la notion de fenêtre glissante - i.e. rolling() - fait du sens pour n’importe quelle donnée, même non-temporelle
reproduisez le dessin ci-dessus, mais
- en ne gardant que le rolling sur 4 semaines
- en indiquant une fenêtre en nombre de points
que constatez-vous aux extrémités ?
exercice 7: resample et rolling¶
- calculez
df2qui se concentre sur la valeur deHighsur la période de Juillet 2018 à fin 2019
plottez-la
rangez dans la variableLle nombre de lignes
# à vousexercice 8: resample+plotting¶
- appliquez à cette série un
resample()avec la moyenne des données sur une période d’une semaine
plottez le résultat
combien d’entrées on devrait y trouver (en fonction de L) si on compare les fréquences des deux séries ?
pourquoi ça ne tombe pas exactement juste ?
est-ce qu’on pourrait estimer ça autrement ?
# à vousexercice 9: rolling+plotting¶
- appliquez à cette série un
rolling()avec une fenêtre de 1 an
plottez le résultat
combien d’entrées on devrait y trouver (en fonction de L) ?
# à vousAnnexe 1 - les échelles de précision¶
un objet datetime64 est créé avec un paramètre unit, qui permet de choisir la précision des calculs; et l’intervalle des dates possibles varie bien entendu avec cette précision :
Annexe 2 - le type de base Python datetime¶
# pour rester cohérent dans le nommage des classes
# je préfère les importer avec un nom conforme à la PEP008
from datetime import (
datetime as DateTime,
timedelta as TimeDelta)# pour modéliser un instant
t1 = DateTime.fromisoformat('2021-12-31T22:30:00')
t1datetime.datetime(2021, 12, 31, 22, 30)# et une durée
d1 = TimeDelta(hours=4)
d1datetime.timedelta(seconds=14400)un peu d’arithmétique¶
# on peut faire de l'arithmétique
# avec ces deux types
# 4 heures après t1
t2 = t1 + d1
t2datetime.datetime(2022, 1, 1, 2, 30)# ajouter, soustraire, multiplier, diviser ...
# 8 haures avant ça, i.e. 4 heures avant d1
t2 - 2 * d1datetime.datetime(2021, 12, 31, 18, 30)# combien de fois 10 minutes dans 4 heures
d1 // TimeDelta(minutes=10)24décomposer¶
pour accéder aux différents éléments d’une date (année, mois, ..), c’est facile
t1.year, t1.hour(2021, 22)d1.days, d1.seconds(0, 14400)à titre plus anecdotique, on peut aussi appliquer directement un format à un instant dans une f-string
# %H c'est pour extraire l'heure
# il y a toute une série de codes de format...
f"{t1:%H==%M}"'22==30'par contre ces formats sont très utiles lorsqu’on va vouloir traduire nos fichiers d’entrée en date/heure
pour une liste complète des formats, voir
https://